Loading
Documentation-as-Code: The Future of Engineering
Discover how documentation-as-code helps engineering teams preserve context, accelerate onboarding, and make AI-assisted development more reliable.

Prince Okon
Senior Data ScientistJun 12, 2026
11 minutes read

THE 2 A.M. TEST
It is 2 a.m. and the payments service is failing for one tenant. The on-call engineer joined four months ago. She finds the ticket that introduced the relevant code — closed eleven months back. She finds the PR — merged the next day. She finds the README — last updated by someone who has since left. The why is in a Slack thread that 404s, a Notion page she does not have permission to read, and the head of an engineer in São Paulo who is, mercifully, awake.
This is not a tooling failure. It is a structural failure of where knowledge was allowed to live. The diff was in one place. The decision was in another. The intent was in a third. The cost of stitching them back together — at 2 a.m., under load — is what we call documentation debt.
Documentation-as-code is the proposition that all three should live in the same place: the repository. The same git history, the same review, the same deploy. The argument is not that wikis are bad. It is that knowledge engineering teams need at the moment of decision must live next to the artifact it explains, or it will not be there when it is needed.
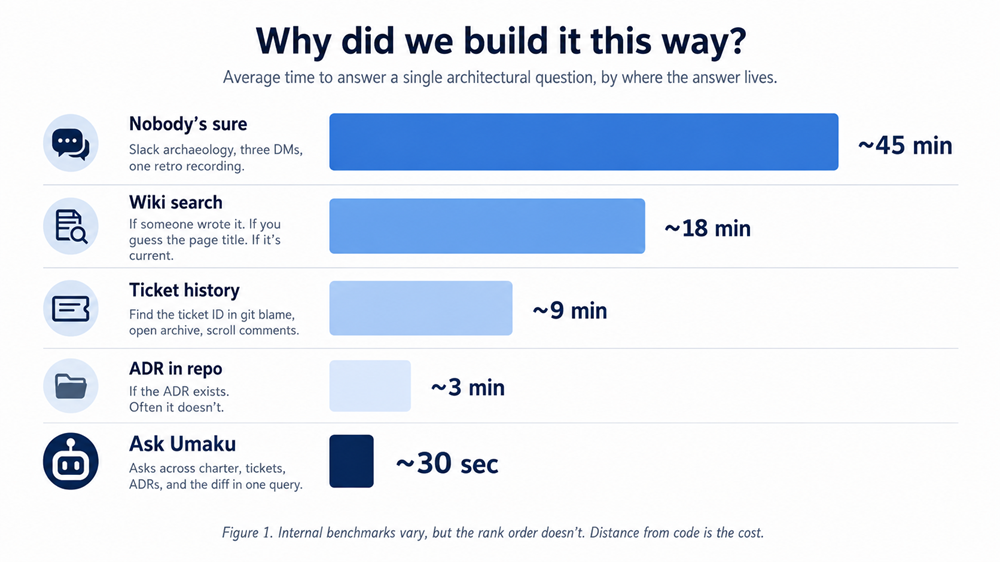
Figure 1. The further documentation lives from the code, the longer the question takes to answer.

The thesis in one line
What Documentation-as-Code Actually Means
The phrase has accreted meaning over a decade and now means different things to different teams. For the purposes of this article it means three concrete things, in this order:
- Engineering knowledge lives in the same repository as the code it explains.
- Changes to knowledge are reviewed in the same pull requests as changes to behaviour.
- All of it — charter, tickets, design notes, comments, diffs — is reachable through a single query surface.
That third one is the part most discussions skip. Moving files into the repo is necessary. Making the resulting graph queryable is what makes it useful.
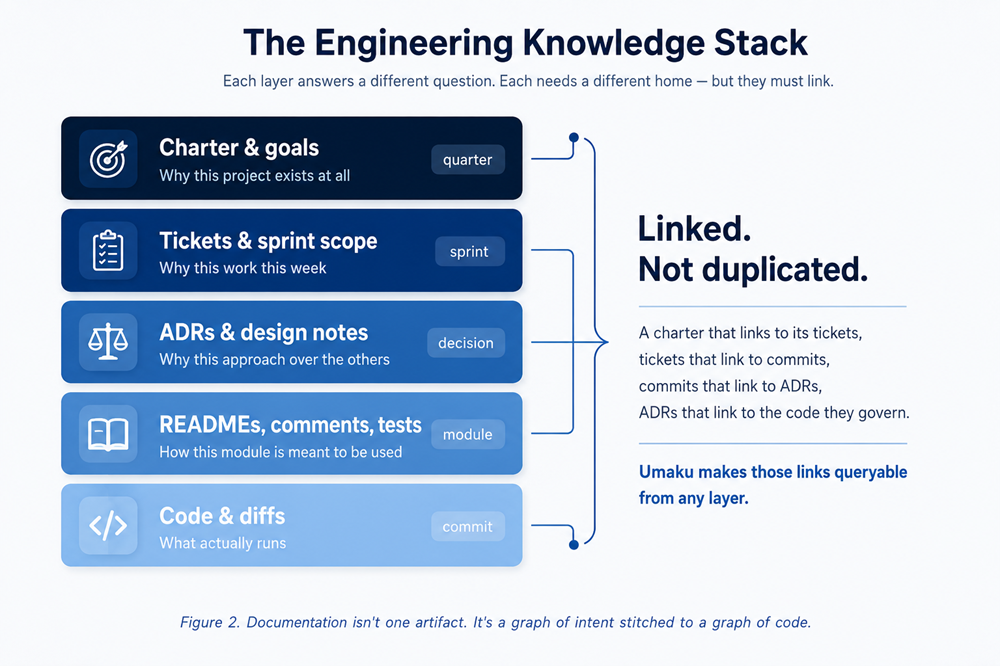
Figure 2. Documentation isn’t one artifact. It’s a graph of intent stitched to a graph of code.
Why This Gets Harder Every Quarter You Wait
Three pressures are compounding. First, codebases are growing faster than the teams that maintain them — modern LLM-assisted development means a six-person team can produce the surface area that took twenty engineers in 2020. Second, the half-life of engineering tenure is shrinking; the senior who knows why leaves before the documentation gets written. Third, AI-augmented review and IDE agents are now reading your repository in real time — and they are only as good as the context they can find.

Hidden cost
Four principles
The teams that have made this transition successfully tend to agree on four things. None of them require a new platform. All of them require discipline.
| 1 | Co-locate intent and artifact
If the README, the ADR, and the runbook do not live in the repo, treat them as not existing. The wiki is for org-level material — values, rituals, the engineering handbook. Everything else moves. |
| 2 | Review docs like you review code
A PR that changes a public interface and does not change its docs should fail review. The reviewer who blocks it is doing the same work as the reviewer who blocks an untested change. Make this a structural rule, not a cultural one. |
| 3 | Make the graph queryable, not the pages searchable
A wiki search rewards people who already know what to search for. A query over tickets, commits, ADRs, and code rewards people who know what they’re trying to do. “Why did we choose Postgres for the events table?” should return the decision, the conversation, the diff, and the reviewer — not a list of pages with the word Postgres. |
Here is what “queryable” looks like in practice. An engineer opens payments/refund_processor.py and wants to know why a stuck refund routes back through the legacy queue when a newer one exists. She does not search the wiki. She does not Slack the team. In her IDE — connected to Umaku via the MCP integration — she asks the chatbot:
| ASK UMAKU
Why does refund_processor.py route stuck refunds through the legacy queue when the new queue exists? |
| CITED ANSWER • 8s
Per ADR-0042 (‘Idempotency via request_id’, approved by Lin on 14 Aug 2025), refunds remained on the legacy queue until the new queue’s idempotency guarantees matched. Ticket UMK-412 (‘Refund stuck-state handling’, owner: Tunde) tracked the partial migration. As of last commit, only Tier-2 tenants have been moved. The original migration plan is in the ticket’s acceptance criteria — PR #1183 (author: Mei) implemented the routing fork. |
No archaeology. No Slack search. No 404. The answer cites the ADR, links the ticket, names the reviewer to ping, and points at the exact PR. Eight seconds versus forty-five minutes — that is the productivity gap the article has been describing. That is what a queryable graph delivers.
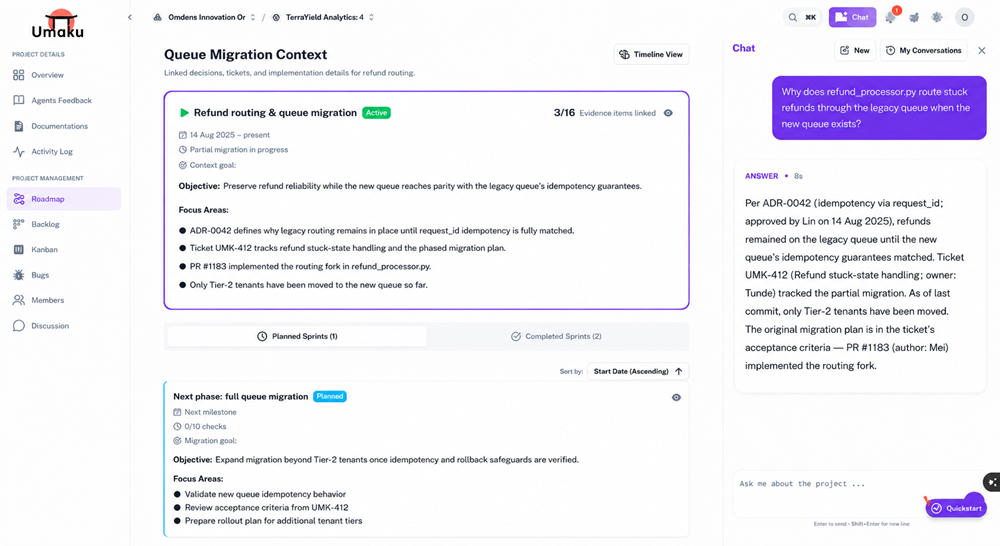
Figure 3. answering a code-context question with the cited response panel
| 4 | Make ownership findable
The diff names the author. The PR names the reviewer. The ADR names the approver. These have always been recorded. They have not been linkable. Linking them turns retro-blame into pre-emptive context. The next engineer to touch the file already knows who to ask. |
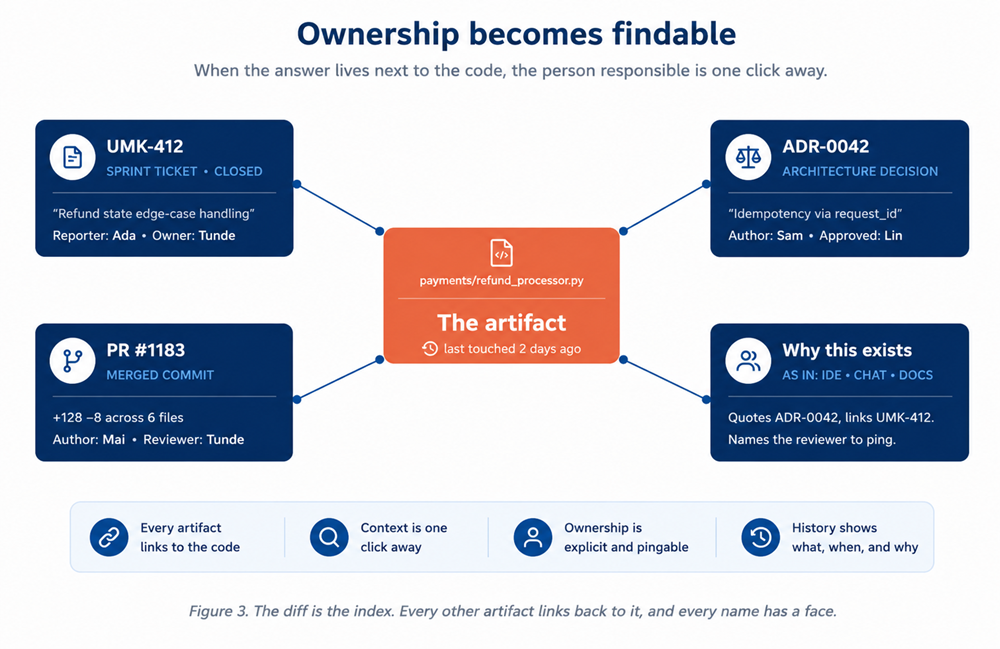
Figure 3. The diff is the index. Every other artifact links back to it, and every name has a face.
Old Shape vs. New Shape
The old question engineering leaders asked was “who owns the wiki?” — a sensible concern when teams were smaller, systems simpler, and knowledge still lived in people’s heads. But modern engineering teams are geographically distributed, codebases outlive their creators, and critical context is often buried in outdated docs nobody can find. Documentation-as-code solves this by keeping answers beside the code they explain, reviewed and updated in the same pull requests, so knowledge evolves with the system instead of drifting away from it.
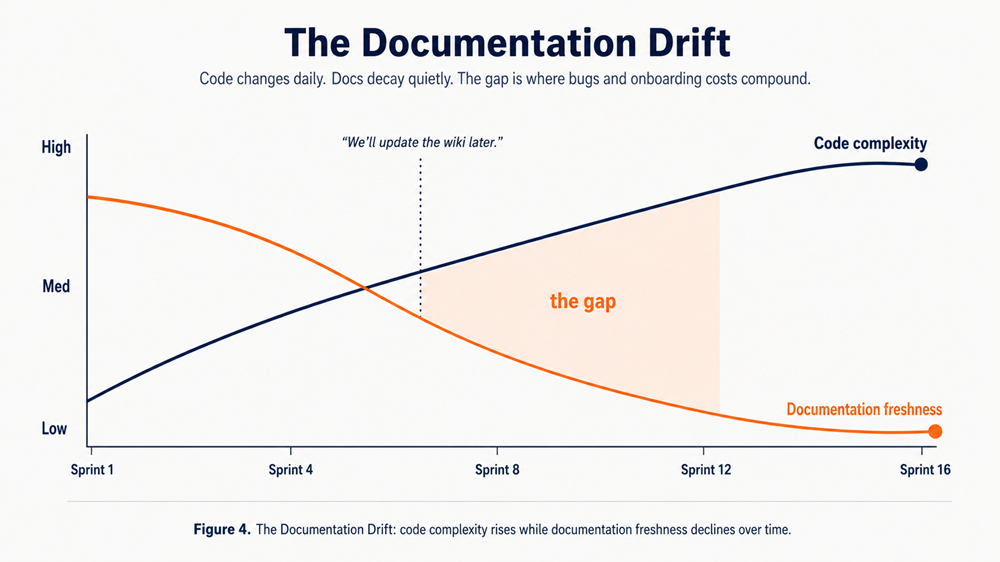
Figure 4. The Documentation Drift: code complexity rises while documentation freshness declines over time
If you want a quick test of whether your organisation operates the new way, walk the columns and count which side describes your engineers’ day.
| Documentation in the wiki | Documentation in the repo |
| Lives in: Notion, Confluence, Drive | Lives in: the same repo as the code |
| Updated when someone remembers | Updated as part of the PR that changed code |
| Reviewed by: nobody, usually | Reviewed by: the same engineers who reviewed the diff |
| Found by: keyword search | Found by: query across charter, tickets, ADRs, code |
| Decays on its own clock | Decays only if the code decays — visible in git history |
| Ownership: implicit | Ownership: linked, named, pingable |
Where Umaku Fits
Umaku is built by Omdena as a context-aware code review platform — not a documentation tool, not a project management tool. It treats the repo, the tickets, the design notes, and the commit history as one corpus and exposes that corpus through a chatbot in the IDE, four post-sprint review agents, and an alignment dashboard.
Forget the feature list. Here is what changes in three specific moments of an engineer’s day.
MOMENT ONE — TUESDAY MORNING, NEW HIRE
Mei joined two weeks ago and is touching billing_webhook_handler.py for the first time. She does not know whether the retry-with-jitter pattern on line 47 was deliberate or a copy-paste from somewhere else. She asks the codebase chatbot. The answer quotes ADR-0017 (decided after the September outage), links the post-mortem ticket, and names the engineer who proposed the pattern. Mei reads the ADR, makes her change with the right defaults, and ships her PR confident she did not silently undo someone else’s mitigation.
MOMENT TWO — FRIDAY AFTERNOON, SPRINT END
Sprint Inclusion runs. It compares the eight tickets the team committed to against the seventeen commits actually merged. Two commits have no ticket — they were patched in mid-sprint. One ticket has no commit — it was descoped but never moved. Alignment score: 71%. The team sees it on the dashboard. They write the descope decision into the ticket before the retro, so the next sprint planning is honest about what shipped.
MOMENT THREE — TUESDAY WEEK, CODE REVIEW
Lin opens a PR that changes the refund flow. Code Quality reads the diff against the module’s docstring (‘a thin adapter — no business logic’). It flags lines 88-104 because the diff introduces a 14-line state machine. Lin agrees. She refactors the state machine into a separate module, updates the docstring, and merges. The next engineer who reads the file sees a thin adapter, as advertised.

Honest Framing
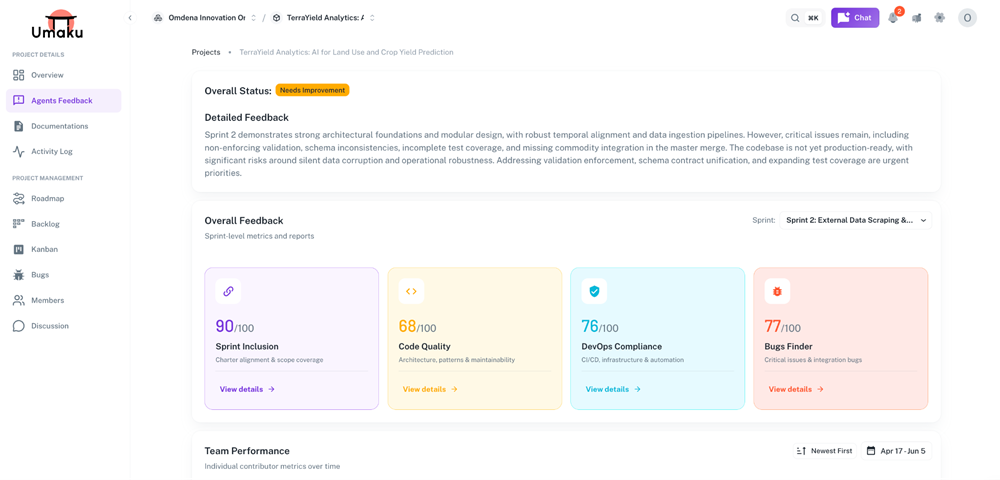
Figure 5. Post-sprint scores from the four Umaku agents — alignment, code quality, devops compliance, bugs.
A 30-Day Rollout
This is a shape teams have used to ship the change in one sprint cycle. Adapt to taste.
WEEK 1 · PICK THE PILOT
One service. The one with the highest on-call frequency or the highest onboarding cost. Move its README, runbook, and any relevant ADRs into the repo. Add a PR template line: “Did this change require a docs update?”
WEEK 2 · ENFORCE REVIEW
Add a CI check that fails a PR touching a public interface without touching its docs. The first week of failures will hurt. By the second week the team will write the doc first.
WEEK 3 · INDEX THE GRAPH
Turn on retrieval over the repo. This can be Umaku, or it can be a homemade RAG layer on a vector store. The point is that an engineer should be able to ask “why is this here” and get a cited answer.
WEEK 4 · MEASURE AND REPORT
Two numbers: alignment (closed tickets that have a matching merged commit) and answer-time (median seconds to answer a sampled architectural question). Both are baselines. Track them per sprint.
The 2 a.m. test, again
Return to the on-call engineer. In the new shape, she opens the failing service’s repo. The README is current — it was updated in the PR that introduced the bug. The ADR is linked from the file. The ticket is linked from the commit.
She opens her IDE and asks the chatbot: “why does refund_processor route stuck refunds back through the legacy queue?” Eight seconds. The answer quotes ADR-0042, links UMK-412, names Tunde as the reviewer, and shows her the test file that was supposed to catch this case but doesn’t.
It is still 2 a.m. The incident is still real. But the reconstruction does not exist any more, because the reconstruction was never necessary. The knowledge was where it needed to be, in the same place as the artifact it explained, ready for the moment someone needed it.
Less archaeology. More evidence.
About Umaku
Umaku is built by Omdena. Field manuals are short, structural pieces written for CTOs, engineering leads, and senior developers thinking about how their teams scale past the people who built them. Comments and pushback welcome.

POWERED BY OMDENA