Loading
Leveraging AI for Accountability in ML Production Pipelines
Why AI/ML teams are turning their pipelines into instruments of evidence — and how the next eighteen months of regulation will force the rest of us to follow.

Prince Okon
Senior Data ScientistJun 1, 2026
15 minutes read

For much of the past decade, production ML has revolved around one dominant verb: deploy.
Ship the model. Keep latency within SLA. Silence the pager. Prove the system can run without breaking. Most tooling followed that priority: packaging models, serving predictions, monitoring uptime, and keeping releases moving. But as ML systems become more consequential, deployment is no longer enough. The harder question is whether every decision, artifact, and behavior in the pipeline can be traced, evaluated, governed, and trusted. That shift now carries real organisational and regulatory weight. The EU AI Act’s high-risk obligations, enforceable from August 2, 2026, and the NIST AI Risk Management Framework’s four functions — Govern, Map, Measure, Manage — both point to the same conclusion: production ML is moving from deployment to accountability.
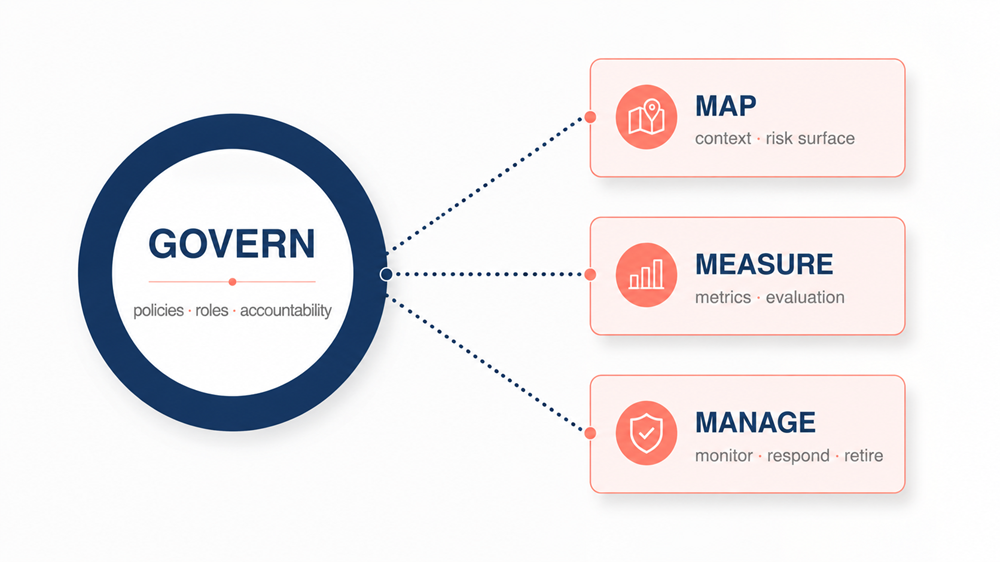
Figure 1. The NIST AI RMF four core functions — Govern is the substrate; Map, Measure and Manage are the operational loops around it. None of them are about deployment.
Notably, none of these functions are deployment functions. They are accountability functions.
They ask different questions: Who approved this system? What risks were mapped before release? Which metrics were used to evaluate it? What controls exist when the model drifts, fails, or behaves unexpectedly? In other words, the centre of gravity in production ML is moving from shipping models to proving that models were shipped responsibly.
The core argument is simple: accountability should not sit beside the ML platform as an external governance layer; it should be built into the pipeline itself, with AI helping to make that accountability continuous, traceable, and operational. This article explores four fronts where that inversion is already taking shape, the open-source practices leading each one, and how they fit into the broader shift toward delivery intelligence.
The Accountability Gap
A production ML pipeline is a directed graph: ingest, validate, transform, train, evaluate, register, promote, serve, monitor, and retrain. Each stage consumes upstream inputs and emits artifacts. By the time a prediction reaches a user, the chain of custody may already be eight to ten links deep.
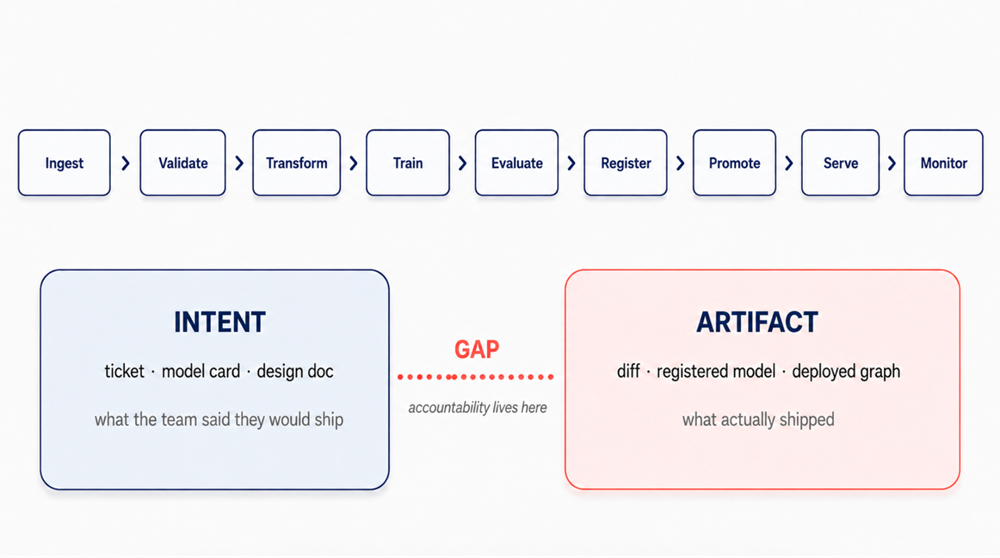
Figure 2. The accountability gap — A working pipeline is a chain of custody eight to ten links long. Intent (ticket, model card, design doc) and artifact (diff, registered model, deployed graph) drift apart in the middle.
The problem appears when something breaks: a bad training batch, feature drift, or a regression against a protected subgroup. At that point, the team has to reconstruct the chain manually, often relying on a senior reviewer who would be required to carry too much of the system’s context in their head.
This is a structural gap. It mirrors the weakness project management tools carried for years: they tracked what humans typed in, not what the work actually did. ML pipelines suffer from the same limitation. The orchestrator knows a DAG ran, but not what the DAG meant, what it promised, or whether the resulting model still matches the model card written two sprints ago. That gap between intent and artifact is where accountability lives or dies. In 2026, ML industry best practices should close that gap on four fronts.
1. Data Lineage as Infrastructure, Not Documentation
The first front is data. A model is, in the most boring possible sense, a compressed function of its training data. If you cannot describe the data that went in — what fields, from what source, what version, under what contract — you cannot describe the model that came out.
OpenLineage is the open standard the industry has converged on. It defines a JSON schema for emitting structured lineage events from any job that touches data, with stable concepts for Run, Job, Dataset, and input/output facets. Spark, Airflow, dbt, Flink, and Beam all emit OpenLineage events natively in 2026; events flow into Marquez or any commercial backend.

Figure 3. Airflow operator with OpenLineage inlets/outlets — lineage is emitted as a side-effect of the run, not a deliverable written up after the incident.
The point is not the YAML. The point is that lineage is no longer a deliverable somebody writes up after the incident. It is an automatic side-effect of running the job. That is the inversion: documentation as code, then documentation as runtime telemetry.
Pair this with data contracts — typed, versioned agreements between producer and consumer of a dataset, enforced at the pipeline boundary — and the input side of the pipeline becomes legible to any reviewer, human or agent, without folklore.
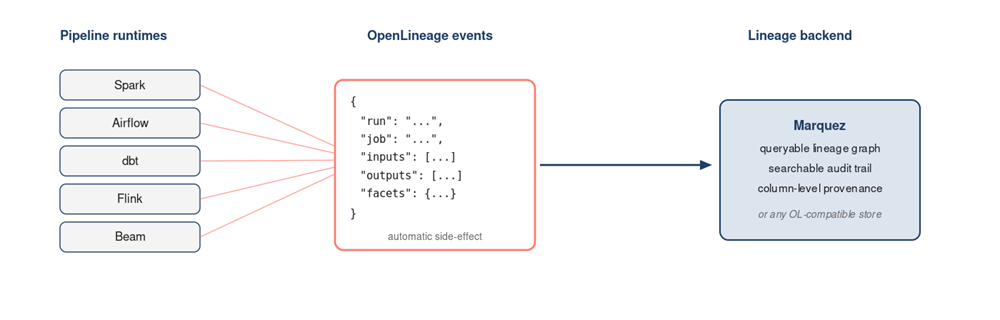
Figure 4. OpenLineage event flow — Spark, Airflow, dbt, Flink and Beam emit a common event schema; events flow into Marquez (or any OL-compatible backend) as a queryable lineage graph.
2. Model Provenance and Gated Promotion
The model has its own lineage problem. Many teams use MLflow’s Model Registry, but fewer treat stage transitions — None → Staging → Production → Archived — as audit events. This situation is changing. MLflow aliases such as @champion and @challenger, combined with tagged metadata, make the lifecycle explicit, preserve a history of who promoted what and why, and reduce rollback to a simple alias swap.
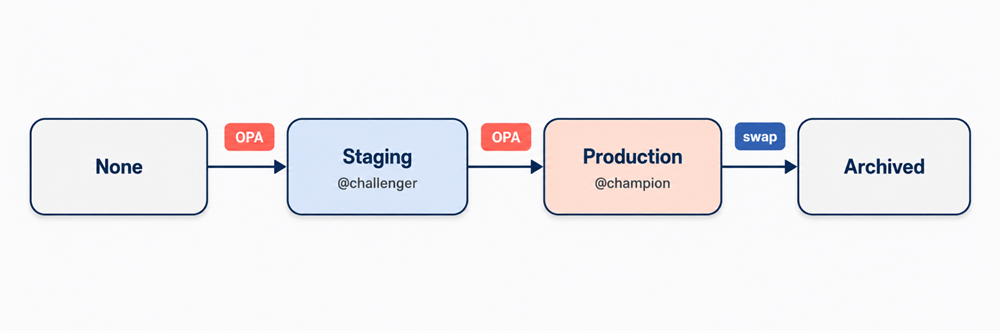
Figure 5. Model lifecycle with gated promotion — MLflow stages plus @champion / @challenger aliases; OPA gates evaluate evidence at every transition. Rollback is one alias swap.
The state-of-the-art move is to gate model promotion with policy as code. Open Policy Agent (OPA) and Rego have become CNCF the standard way to express those controls as executable rules like this:

Figure 6. Promotion policy in Rego (Open Policy Agent) — a model cannot enter Production unless every clause holds; missing evidence becomes a hard stop.
Mature teams run these gates twice: first in CI for fast developer feedback, then again at admission time for final enforcement. A model goes into production only when its model card exists, its training data meets the required contract version, its holdout evaluation has run, and its fairness metrics remain within policy bounds. The pipeline stops being a chain of best-effort checks. It becomes a chain of evidence, where every promotion is justified and every missing artifact blocks release.
3. Continuous Evaluation and Drift, in the Loop
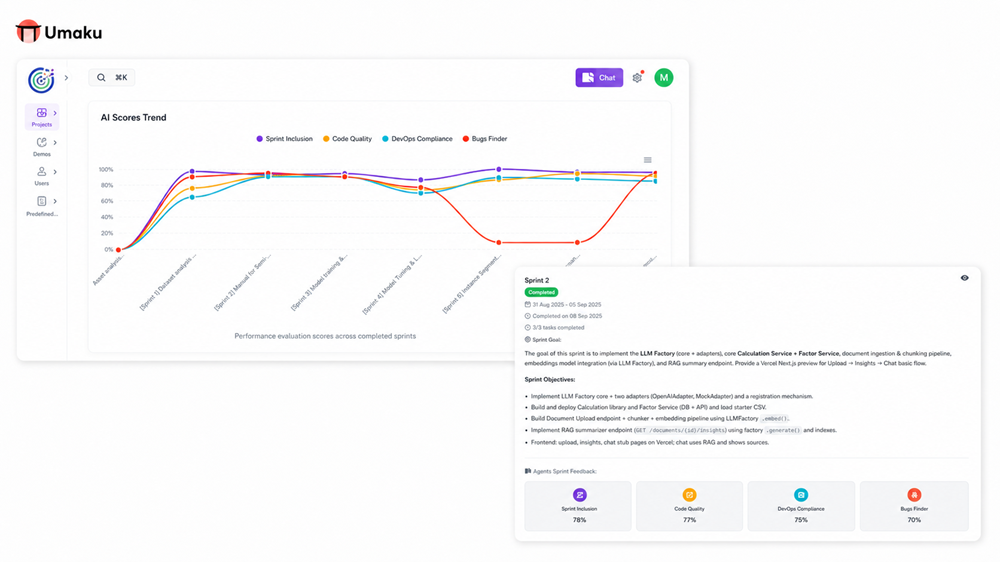
Figure 7. Delivery Accountability Signals Before Production Risk Escalates
Umaku’s AI Scores Trend and Completed Sprint Feedback views surface delivery risks across quality, DevOps compliance, scope alignment, and potential bugs over multiple delivery cycles. This creates an upstream accountability layer that complements post-deployment observability. Where live ML observability tools detect drift, silent failures, and production anomalies after deployment, Umaku helps teams identify execution risks earlier, before they compound into production issues.
The third accountability front is post-deployment observability, where many of the most serious failures eventually appear. As a 2022 VLDB paper noted, sustaining ML applications after deployment is difficult because teams often lack real-time feedback on predictions, while silent failures can occur at any component of the pipeline. Four years later, the tooling has improved, but the underlying failure mode remains largely the same. This is where tools like Evidently AI have become important. Evidently has emerged as a widely used open-source option for monitoring data drift, model performance, and data quality. The same library that generates an HTML drift report for an analyst can also run directly inside a prediction pipeline as a test suite, blocking a rollout when drift on a protected feature exceeds an agreed threshold.
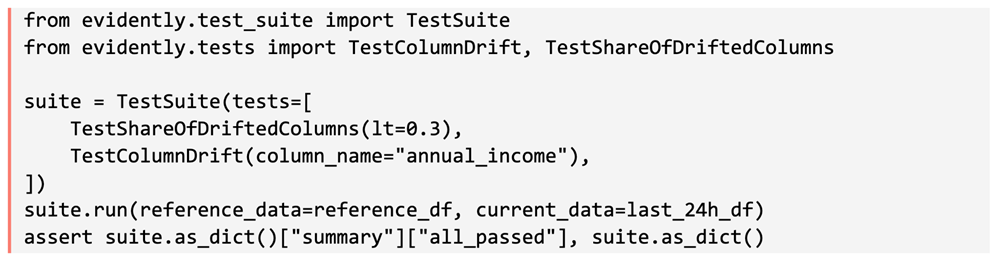
Figure 8. Evidently test suite run inline in a prediction pipeline — the same library that renders an analyst-facing HTML report runs as a CI gate; failure blocks the rollout.
The more interesting move in 2026 is to take drift out of “alert fatigue” territory and treat it as a contract violation. If a data contract defines an acceptable distribution band for a feature, drift detection becomes enforcement. If the contract is silent, the issue is routed to the upstream owner — and the lineage graph should already identify who that is. The investigation loop closes in minutes, not days.
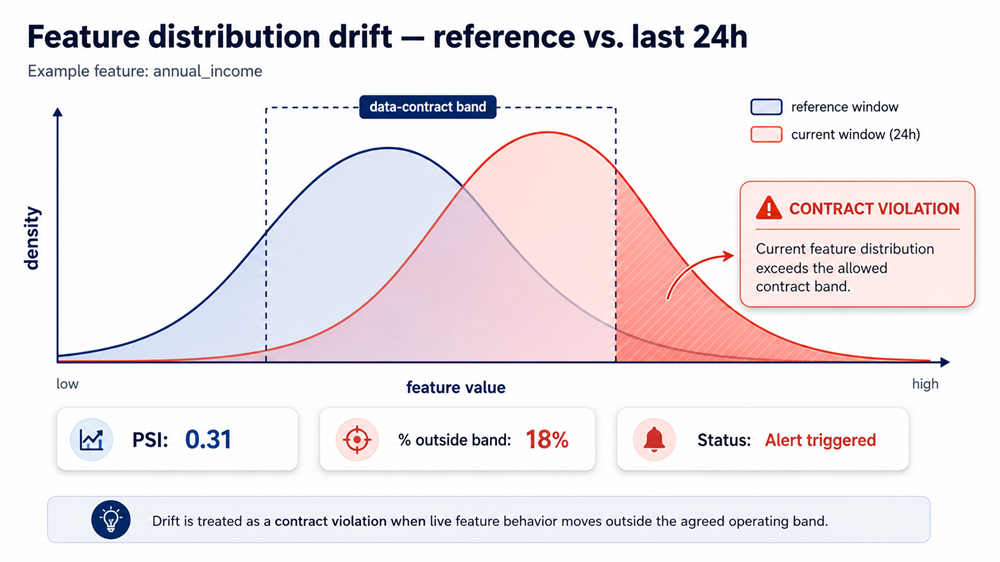
Figure 9. Drift as a contract violation — Reference vs. current feature distribution: the data contract band defines what is in-policy. Shift outside the band is enforcement, not an alert.
4. AI-Assured Review — Closing the Intent-vs-Reality Gap
The first three fronts make the pipeline legible. The fourth is what makes it accountable, and it is the one most teams haven’t built yet: an AI review layer that compares what was promised — in the ticket, the model card, the design doc — against what was actually shipped — the diff, the registered model, the deployed graph.
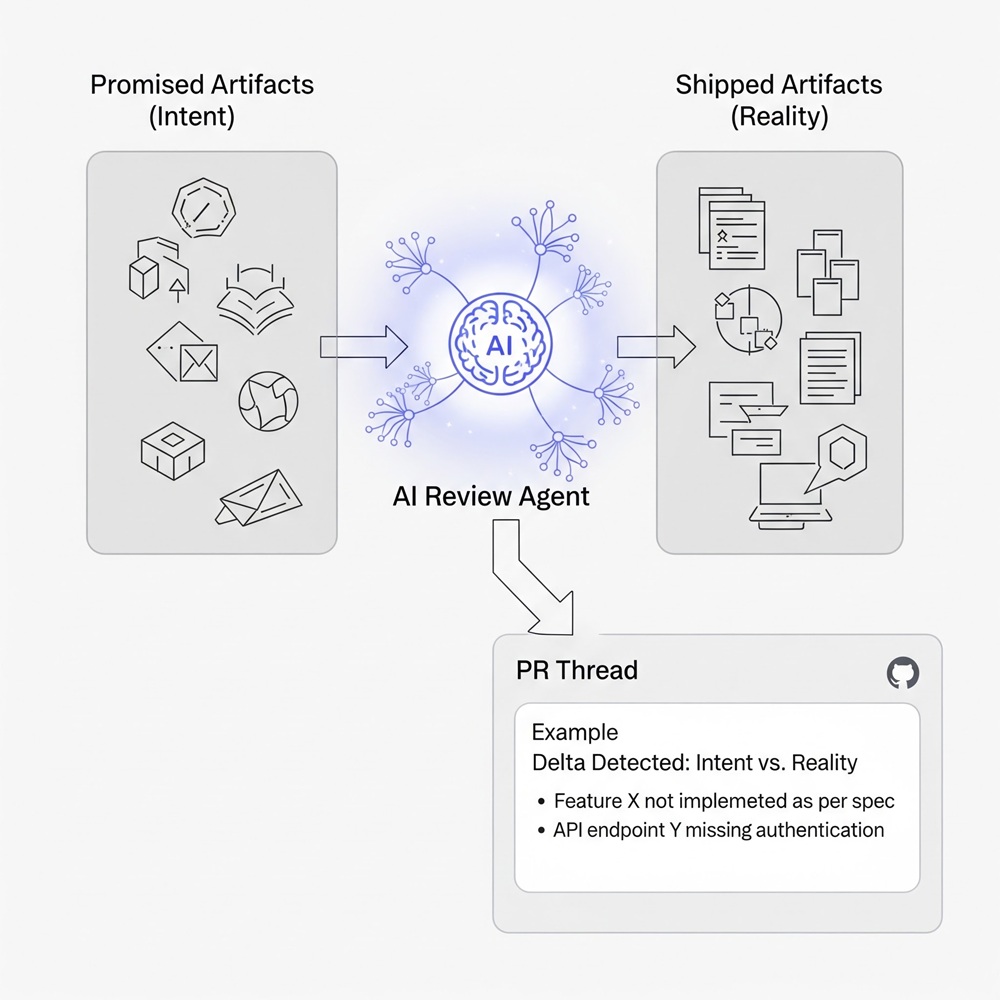
Figure 10. The AI review layer sits between intent and shipped — promised artifacts on the left, shipped artifacts on the right; the review agent reads both sides and posts the delta into the PR thread at the moment of commit.
This is the most under-hyped of the four shifts: specialist review systems that can read both intent and artifact, then flag issues at the moment of commit.
- Sprint alignment. Did this sprint’s diffs actually implement the user stories that were planned, or did scope quietly compress? An alignment score — the fraction of committed work that maps cleanly to charter intent — may be uncomfortable in the first few sprints, but it becomes sharper after three or four cycles.
- Code quality. Does the new training or serving code meet the team’s standards for modularity, typing, and test coverage? Instead of surfacing vague concerns in a retro deck three weeks later, concrete before-and-after refactor suggestions appear directly in the PR thread.
- DevOps compliance. Does the change include the .env.example, Dockerfile, and .github/workflows entry it needs, or is the deployment artifact silently incomplete? A model that retrains correctly on a laptop but fails on the cluster is a governance failure before it is only an engineering failure.
- Bugs and silent failures. Is there an unhandled exception path in the new feature handler, a missing health check, or a regression introduced three sprints ago that nobody noticed? Specialist agents encode the structural memory that usually lives in one senior reviewer’s head — and leaves when they do.

Figure 11. Four post-sprint review agents — structural memory as infrastructure — scoped reviewers running on every commit; each encodes a slice of the questions a senior engineer asks at 11pm on a Thursday and forgets to write down.
These are the questions a staff engineer asks during a code review at 11pm on a Thursday and forgets to write down. Encoding them as agents — not as opaque general-purpose AI, but as practical, scoped reviewers that run on every commit — turns a team’s structural memory into infrastructure. The blast radius when the principal engineer goes on leave shrinks materially.
This is the bridge between the MLOps governance stack and the everyday flow of work, and it is the bridge most pipelines are still missing.
The Pattern: Pipelines as Evidence
Read across the four fronts and a pattern appears. The traditional pipeline is a sequence of transformations and a list of side-effects. The state-of-the-art pipeline is a sequence of transformations, a list of side-effects, and an emitted graph of evidence: lineage events, model card hashes, evaluation run IDs, policy decisions, drift reports, AI-generated review notes — all addressable, queryable, and versioned alongside the code.
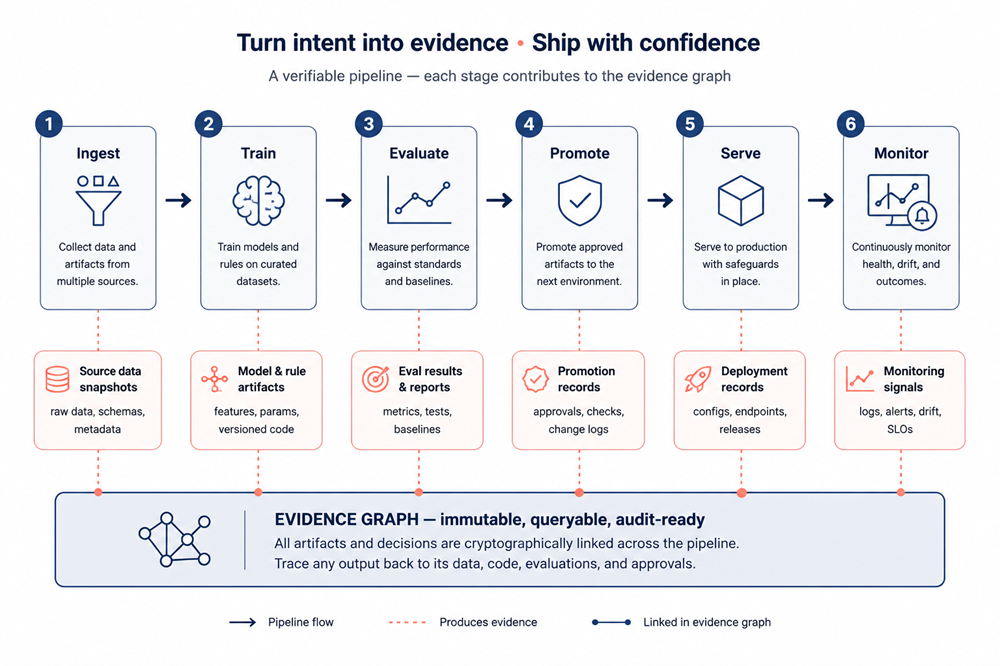
Figure 12. Pipelines as evidence — every stage emits a typed evidence artifact as a side-effect; the union is a single, queryable graph that satisfies both the auditor and the CTO with one artifact.
That graph is what auditors will ask for when the EU AI Act’s Article 12 logging requirements meet a CTO’s quarterly review. It is also what gives an engineering leader something better than the standup-and-pray approach to knowing whether the team shipped what it said it would ship. One artifact serves both readers.
The cultural shift is the same shift happening in project management more broadly: from after-the-fact (audits, retros, post-mortems) to in-the-loop (gates, agents, contracts). Less reconstruction. More evidence at the moment of action.
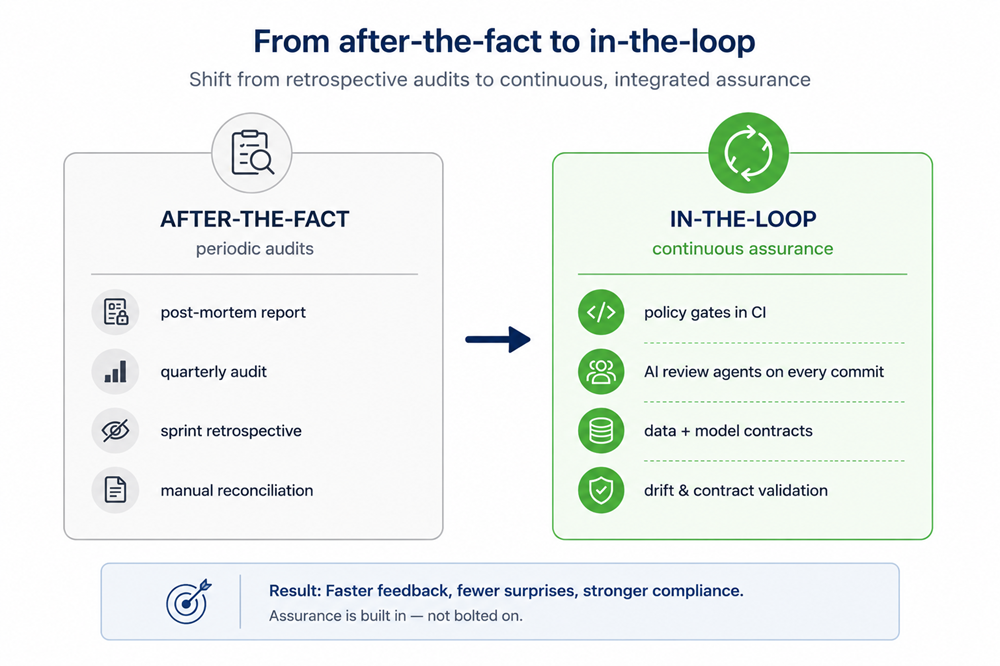
Figure 13. From after-the-fact to in-the-loop — the previous era reconstructed accountability after deployment; the state-of-the-art era enforces it at the moment of action.
Why This Still Needs Accountable Partners
The tools are open source, but accountability is not a tooling problem alone. OpenLineage, MLflow, OPA, and Evidently can help teams capture evidence, enforce policies, and monitor systems, but they do not decide which policies matter, what fairness threshold is appropriate, or who is responsible when a model card diverges from the deployed artifact. That work requires contextual judgement. It means translating a domain, regulation, and deployment environment into contracts, policies, and audit graphs that can withstand real scrutiny. AI can accelerate that work, but it cannot replace accountable partners with domain credibility.
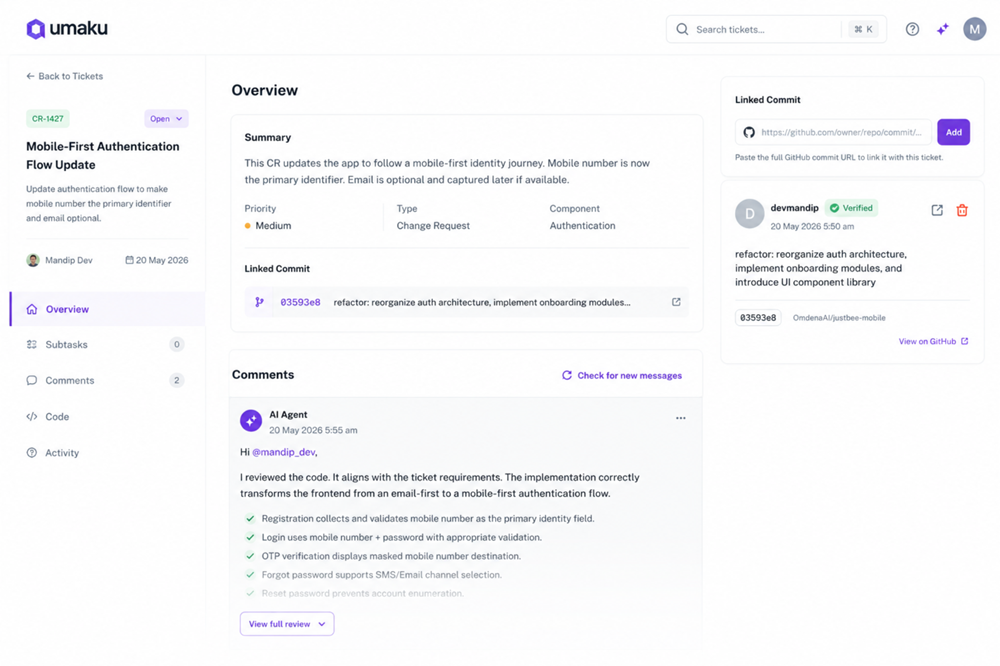
Figure 14. Umaku AI agent feature lets you interact with your project within context — Context is obtained from project documentation and posted code
This is where Omdena fits. Since 2019, Omdena has delivered 300+ production-ready AI solutions across 80 countries, often in high-stakes areas such as climate, health, and development. Umaku extends that delivery experience into the everyday engineering workflow, connecting tickets, commits, sprint reviews, code quality, DevOps compliance, and bug detection into one context-aware platform. In short, the future is not just operational ML pipelines. It is an accountable delivery infrastructure — and Umaku is one expression of that shift.
Quick Smoke Test
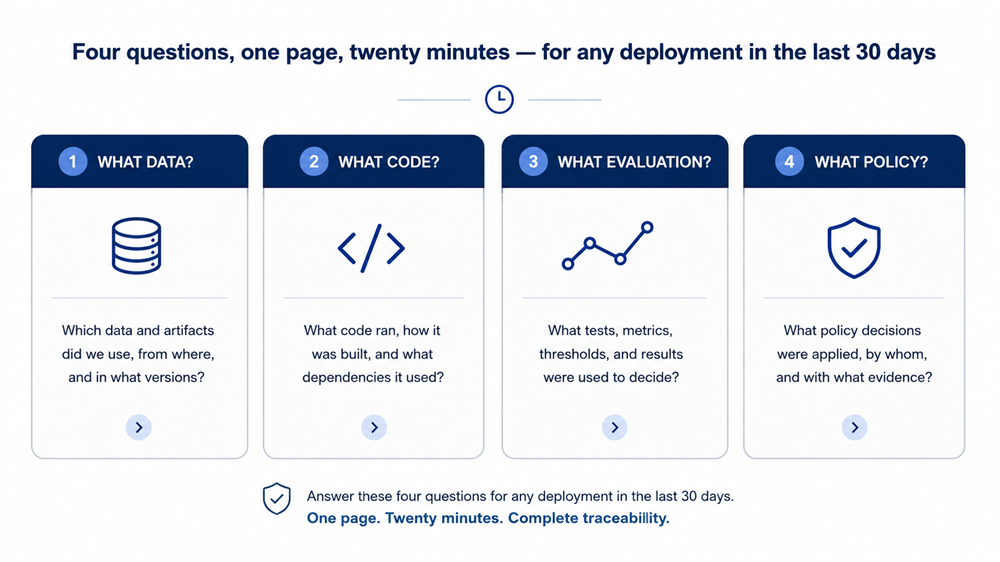
Figure 15. The four-question accountability card — the single-page test for any deployment from the last 30 days. If you can’t answer all four, your pipeline is missing evidence the regulator will ask for.
Pick any model deployed by your team and answer four questions on one page — what data, what code, what evaluation, what policy? If your team cannot do that in 20 minutes, you are still operating in the old era — and by August 2, 2026, that will no longer be defensible.
References
- NIST AI Risk Management Framework (AI RMF 1.0), January 2023. nist.gov/itl/ai-risk-management-framework
- Regulation (EU) 2024/1689 — EU Artificial Intelligence Act, Official Journal of the EU. eur-lex.europa.eu
- EU AI Act implementation timeline (high-risk obligations enforceable Aug 2, 2026). artificialintelligenceact.eu
- EU AI Act, Article 12 — Record-keeping / logging requirements. artificialintelligenceact.eu/article/12
- ISO/IEC 42001:2023 — AI management systems. iso.org/standard/81230.html
- OpenLineage specification (open standard for lineage events). openlineage.io
- Marquez — reference OpenLineage metadata backend. marquezproject.ai
- Apache Airflow OpenLineage provider. airflow.apache.org/docs/apache-airflow-providers-openlineage
- Jones, A. Driving Data Quality with Data Contracts, O’Reilly, 2023. oreilly.com
- MLflow Model Registry (stages, @champion / @challenger aliases, registered-model history). mlflow.org/docs/latest/model-registry.html
- Open Policy Agent (OPA) — CNCF graduated project. openpolicyagent.org
- Rego policy language. openpolicyagent.org/docs/latest/policy-language
- Mitchell, M., et al. “Model Cards for Model Reporting.” FAT* 2019. arxiv.org/abs/1810.03677
- Gebru, T., et al. “Datasheets for Datasets.” Communications of the ACM, 2021. arxiv.org/abs/1803.09010
- Evidently AI — open-source ML & LLM observability framework. github.com/evidentlyai/evidently
- Evidently documentation. docs.evidentlyai.com
- Shankar, S., et al. “Towards Observability for Production Machine Learning Pipelines.” VLDB 2022. (Source of the “silent failures … at any component of the pipeline” quote.) arxiv.org/abs/2108.13557
- Brand Identity on Omdena 2026-2027 (Omdena internal positioning document) — source for the “trusted human layer that governs, validates, and contextualizes AI outputs” framing.
- Umaku 60-Day Work Plan — Tech Marketer, Omdena Inc. — source for the four-agent architecture (Sprint Inclusion, Code Quality, DevOps Compliance, Bugs Finder) and Ticket ↔ Commit differentiator.
- From Task Tracking to Delivery Intelligence — Omdena/Umaku essay — source for the delivery intelligence framing and the after-the-fact → in-the-loop cultural shift.
- Omdena — omdena.com — 300+ production-ready AI solutions since 2019, partners include UN, NASA, Microsoft.
Umaku — context-aware AI-driven development platform, Built by Omdena.