Loading
The Missing Layer in Modern Software Delivery
Most production failures come from missing evaluation, observability, guardrails, and governance. Learn how to build production-ready AI systems.

Prince Okon
Senior Data ScientistJul 3, 2026
13 minutes read

Production AI is less about the model and more about evaluation, observability, guardrails, and governance — and the same is true for every other sprint you ship.
For CTOs & Engineering Leads · Umaku field notes
Software delivery has two visible layers — the features your team builds and the infrastructure they run on — and one invisible layer in between. That invisible layer is where evaluation, observability, guardrails, and governance live. It is where most production incidents originate. This article names the layer, breaks it into its four pillars, and shows how Umaku’s DevOps Compliance agent turns it from a checklist of good intentions into a score the team cannot deploy without.

Figure 1. The missing layer sits between feature work and infrastructure. Most teams ship the layers above and below it. The middle is where incidents live.
Friday afternoon. The sprint review goes perfectly. Tests are green. The demo works. The stakeholders applaud. The team marks the feature complete and goes home. Monday at two in the afternoon, the on-call engineer pages the rest of the team because production traffic just exposed the four things the demo could not show: there is no runbook for the new service, the alarms do not cover the cascade path, the new queue does not have a dead-letter queue, and the ownership row in the wiki reads TBD.
The sprint shipped feature is complete. It did not ship production ready. There is a difference, and the difference is the missing layer.
1. The two layers everyone sees — and the one in between
Modern engineering organisations have spent a decade getting good at two layers.
On top, the feature layer: code, tests, demos, PR review, sprint planning, all the things that show up on the velocity dashboard. This is the layer AI tools made dramatically faster over the last eighteen months.
Underneath, the infrastructure layer: the cluster, the queues, the storage, the CI/CD pipeline, the cloud. This is the layer the platform team owns, and it is mature.
Between them sits the layer this article is about. It does not show up cleanly on any one team’s roadmap. The feature team assumes the platform handles it; the platform team assumes the feature team handles it. Neither does. Both ship faster. The middle layer gets thinner sprint by sprint, and the incidents quietly accumulate against it.

Figure 2. The same sprint, scored two different ways. Most teams stop at the column on the left. The column on the right is the gate Umaku DevOps Compliance enforces.
2. The four pillars of production readiness
Strip away the jargon, and the missing layer is four questions. Each one is the difference between a feature that works on the demo and a feature that survives Monday.
Pillar 1 — Evaluation. Does the code behave correctly under the conditions production will actually present? Umaku evaluates this by running each diff against an offline benchmark, a canary plan, and the linked ticket’s acceptance criteria.
Pillar 2 — Observability. Can the team see what the code is doing once it ships? Umaku evaluates this by checking that logs, traces, and metrics on the critical paths exist before the deploy is allowed.
Pillar 3 — Guardrails. What stops a small problem from becoming a cascade? Umaku evaluates this by enforcing dead-letter queues, rate limits, circuit breakers, and a tested rollback for every infra change.
Pillar 4 — Governance. Who owns this, who reviewed it, who is on the hook when it pages at 3am? Umaku evaluates this by requiring a named owner, an escalation path, an audit trail of approvals, and an ADR for any architectural change.

Figure 3. The four pillars. Skip a pillar, ship the gap. Skip a pillar twice, ship the incident.
| THE THESIS IN ONE LINE
Production readiness is not a vibe. It is a score across four pillars, and Umaku DevOps Compliance computes it every sprint. |
3. Why this matters most for production AI — and why the lesson generalises
The clearest illustration of the missing layer is what is happening to teams shipping LLM-powered services right now.
The intuitive concern with production AI is the model: it might hallucinate, it might drift, it might disappoint on a hard prompt. But when you read the post-mortems of real production AI incidents — Anthropic’s, OpenAI’s, the long tail of fintech and healthtech systems that quietly leak — the model is rarely the root cause. The root cause is almost always the layer around the model: an evaluation harness that did not catch the regression, an observability gap that delayed detection, a missing guardrail that let a single failure cascade, or a governance gap that meant nobody knew who could roll the model back.
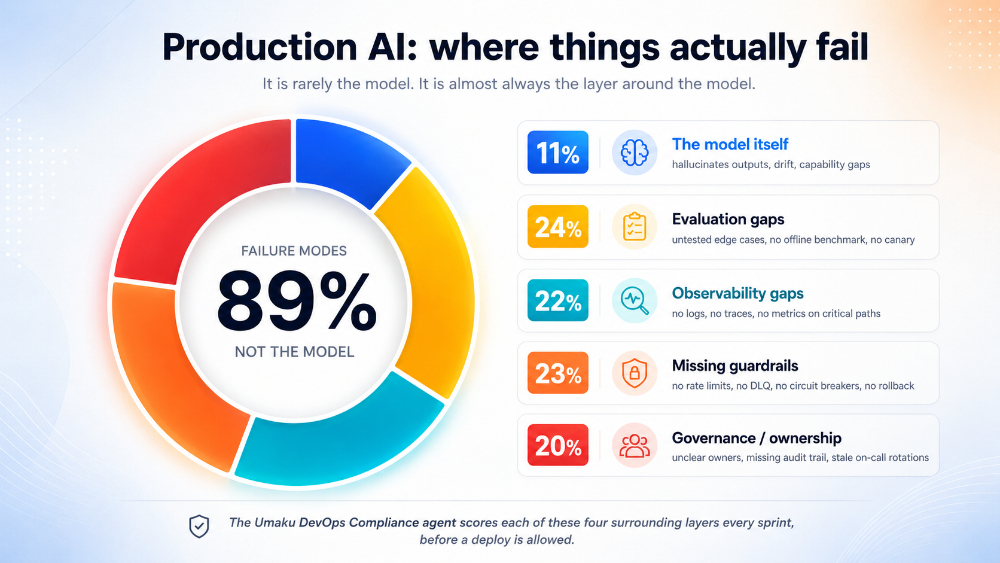
Figure 4. Where production AI actually fails. Eleven percent of failures are about the model. The other eighty-nine are about the layer this essay is naming.
This is uncomfortable for teams that have invested heavily in model selection and prompt engineering. It is also liberating: the levers you control are larger and more durable than you thought. You can change the model in eighteen months. You can fix the evaluation harness this sprint.
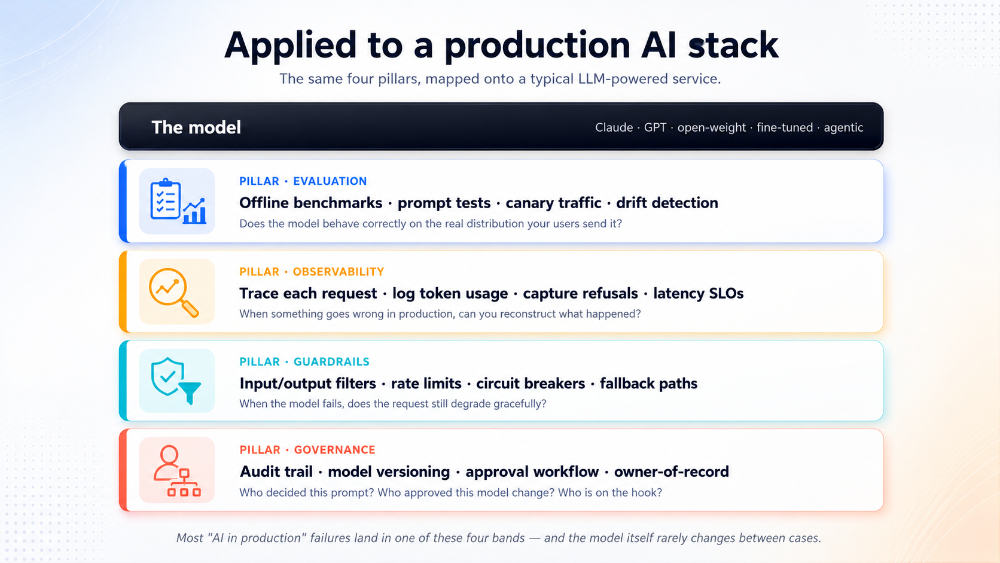
Figure 5. The same four pillars, mapped onto a production AI stack. The model is one band of five. The other four are where the work is.
The reason the AI-production example matters is that it is the same shape as every other sprint. A web service that ships without alarm coverage will fail the same way an LLM service does. A payment flow that ships without a tested rollback will fail the same way an inference service does. Evaluation, observability, guardrails, and governance are not AI concepts. They are software delivery concepts that production AI happens to surface most painfully.
4. What “feature complete” actually leaves out
Here is the five-line checklist that does not appear on most teams’ definition of done — and the cost of each line item when it shows up in the incident review.
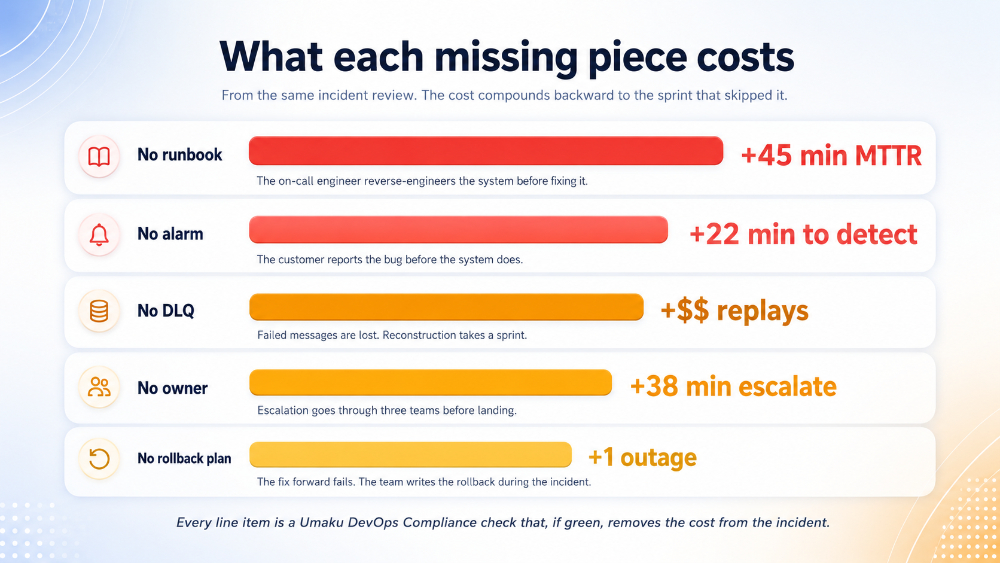
Figure 6. Each missing piece becomes a cost in the incident review. Every line is a DevOps Compliance check that, if green, removes the cost.
Read the chart carefully. The total cost of skipping these five items is roughly two engineer-days of incident time, an extra outage window, and the customer-facing damage of a public failure. The cost of doing the items in the sprint is roughly two engineer-hours.
The math is identical to the unit-test argument from 2013. The shift is that in 2026 the cost of writing the items dropped — AI can scaffold a runbook, an alarm, a DLQ wiring — while the cost of skipping them rose, because AI-augmented teams ship more changes per sprint, which means more surfaces that need each item.
5. The Umaku DevOps Compliance module
Umaku’s DevOps Compliance agent reads each sprint’s work against a sixteen-item checklist, scores it out of one hundred, and refuses to call the sprint deployable until the score clears a threshold the team sets. It is the missing layer, made tangible.
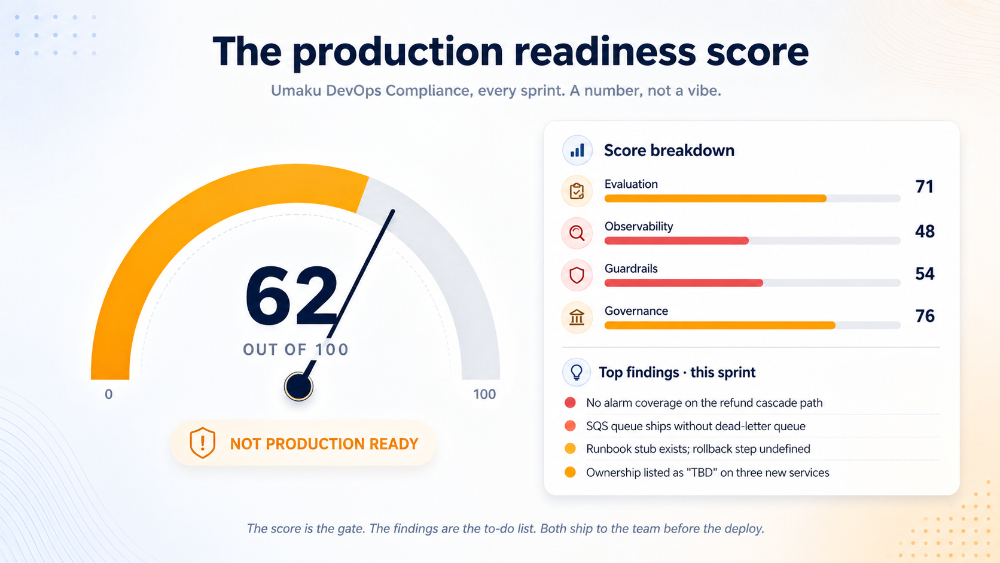
Figure 7. The production readiness score, broken down by pillar. The findings panel turns the number into a to-do list.
Three things make this different from a static checklist.
It reads the diff, not the doc. DevOps Compliance does not ask the team to fill in a template. It reads the actual code change, the actual Terraform diff, the actual ticket scope, the actual ADR references, and the actual existing runbook. If you added a queue but did not configure a DLQ, the agent sees that — not because someone remembered to flag it, but because the diff did.
It is sprint-scoped, not deploy-scoped. The check runs at the end of the sprint, not at the moment of deploy. Teams catch the gaps while the engineer who made the change still has the context to fix them — not three weeks later when someone hands the on-call rotation a system they did not build.
It surfaces the findings as a queryable corpus. The findings are not a PDF. They are a structured list the same chatbot reads. A senior engineer can ask:
| ASK UMAKU
Is this sprint production ready? |
| DEVOPS COMPLIANCE · cited findings
Current score: 62 / 100 — below the 80 deploy gate. Top blocking findings: (1) No alarm coverage on the refund cascade path — see ADR-0042 for the contract this violates. (2) The new refund_retries SQS queue ships without a dead-letter queue — see PR #1183 line 47. (3) Ownership listed as TBD on three new services. Recommend: block deploy. Estimated effort to clear: 2 engineer-hours. |
Six lines. Cited. Linked to the specific PR, the specific line, the specific ADR. The conversation moves from “are we ready?” to “here are the three things to do before we ship.”
6. What the score actually contains
Sixteen items, four per pillar. None of them are exotic. All of them are the items the on-call retro will name three weeks from now if the team skipped them.

Figure 8. The full checklist. Each item is either green or it is a blocker.
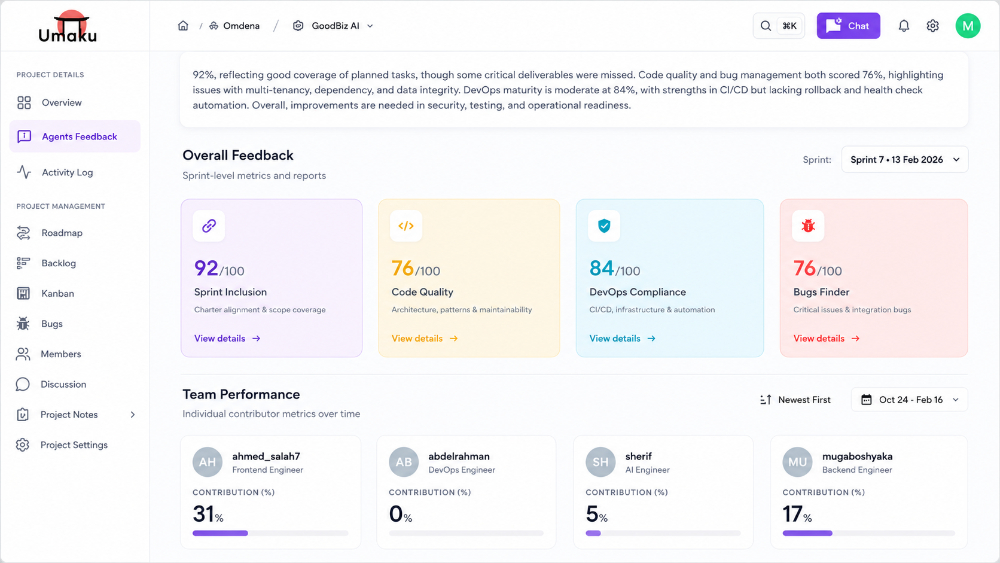
Figure 9. The four post-sprint agents in the Umaku product. DevOps Compliance is the teal score. Code Quality, Sprint Inclusion, and Bugs Finder run alongside it.
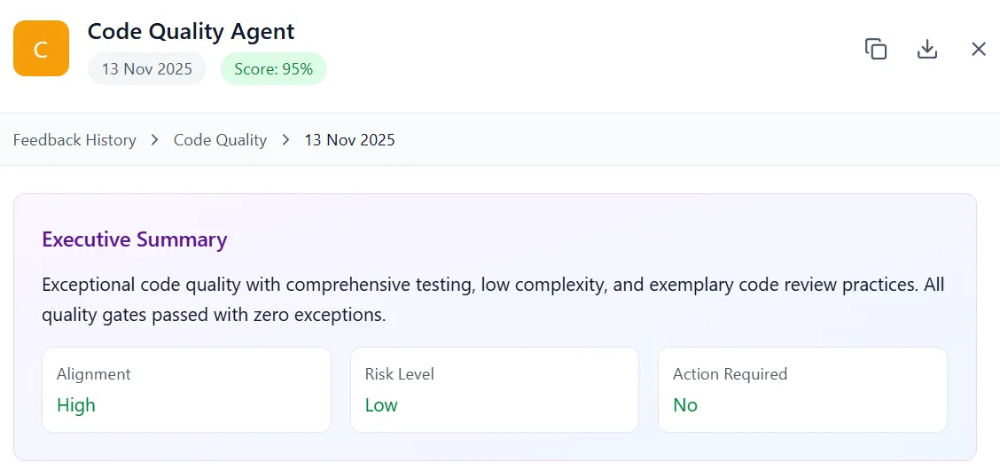
Figure 10. Agent detail view. Score, alignment risk, specific findings, recommended actions. DevOps Compliance follows the same pattern, scored against its sixteen-item checklist instead of Code Quality’s contract checks.
7. The compounding effect — what happens after twelve sprints
The first sprint a team adopts the DevOps Compliance gate is uncomfortable. The score is sixty-two. Engineers grumble about being slowed down by alarms and runbooks. The next sprint is seventy-four. The third is eighty-three — clearing the gate for the first time. By sprint six the score is steady in the high eighties; by sprint twelve it is ninety-one and stable.
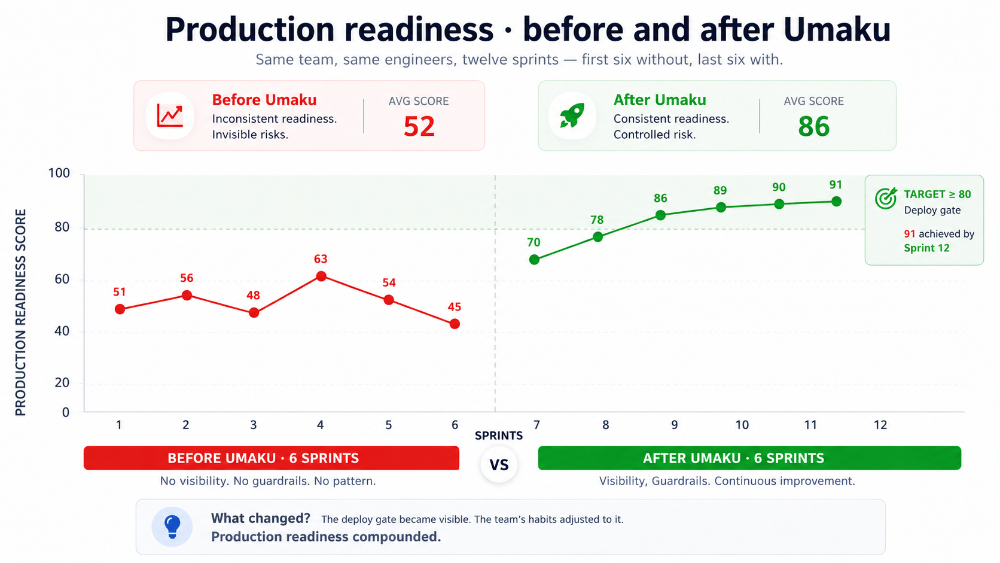
Figure 11. Production readiness scores across twelve sprints. Same team, before and after the gate becomes visible.
The score is not the outcome. The outcome is what happens to the incident count when the score stays above the gate.
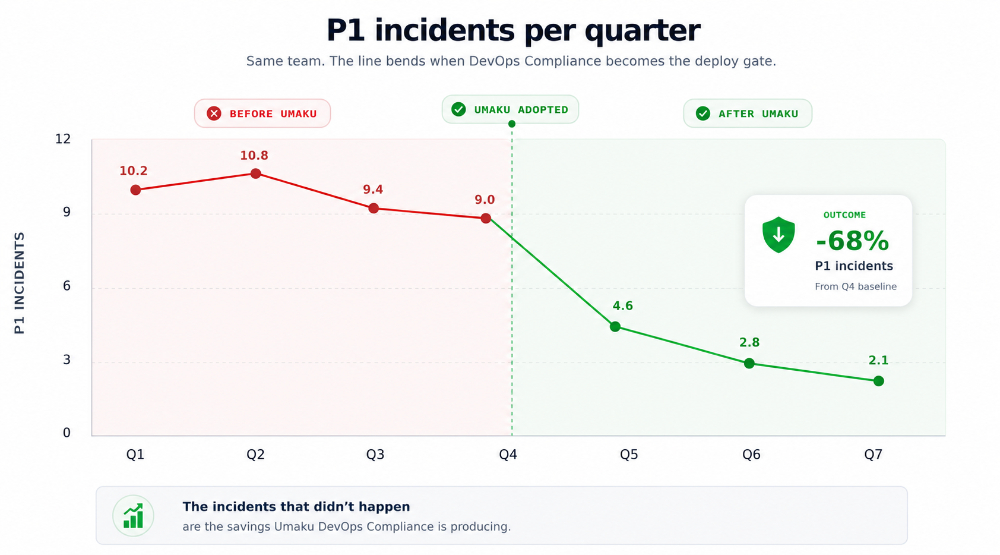
Figure 12. P1 incidents per quarter. The line bends at the moment DevOps Compliance becomes the deploy gate.
A sixty-eight percent reduction in P1 incidents is a number the CFO can do arithmetic on. It is also conservative — the indirect savings (the engineering hours that are not spent on incident reviews, the customer churn that does not happen, the on-call rotation that does not burn out) compound on top.
8. Where this fits in the rest of the workflow
DevOps Compliance is one of four post-sprint agents in Umaku. The other three are Sprint Inclusion (alignment between planned and shipped), Code Quality (scope drift in the diff), and Bugs Finder (logical-bug patterns).
The four together form a single loop — sprint plan → build → compliance check → deploy → operate — with findings from production flowing back into the next sprint’s plan. The loop is what makes the missing layer durable rather than a one-time push.
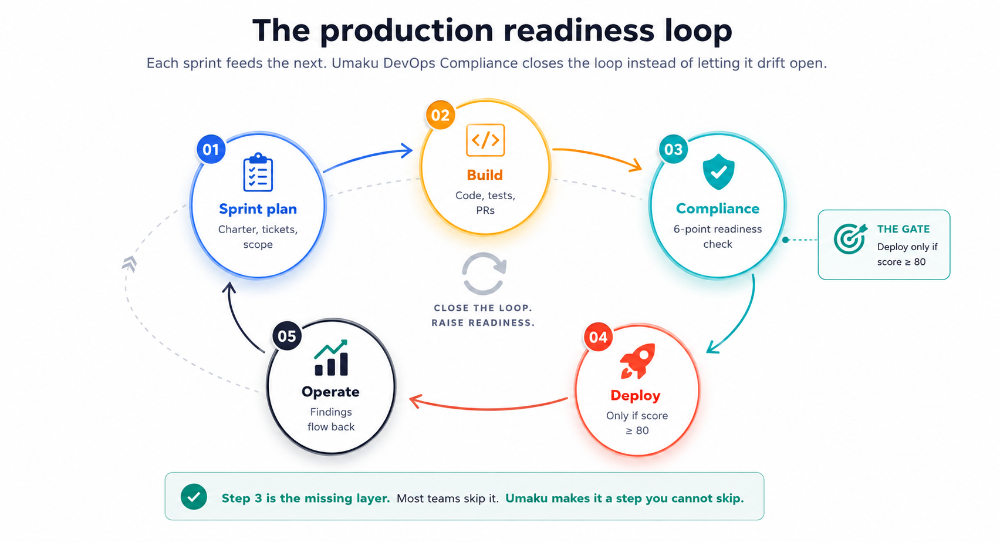
Figure 13. The production readiness loop. Step three is the missing layer. Most teams skip it. Umaku makes it a step you cannot skip.
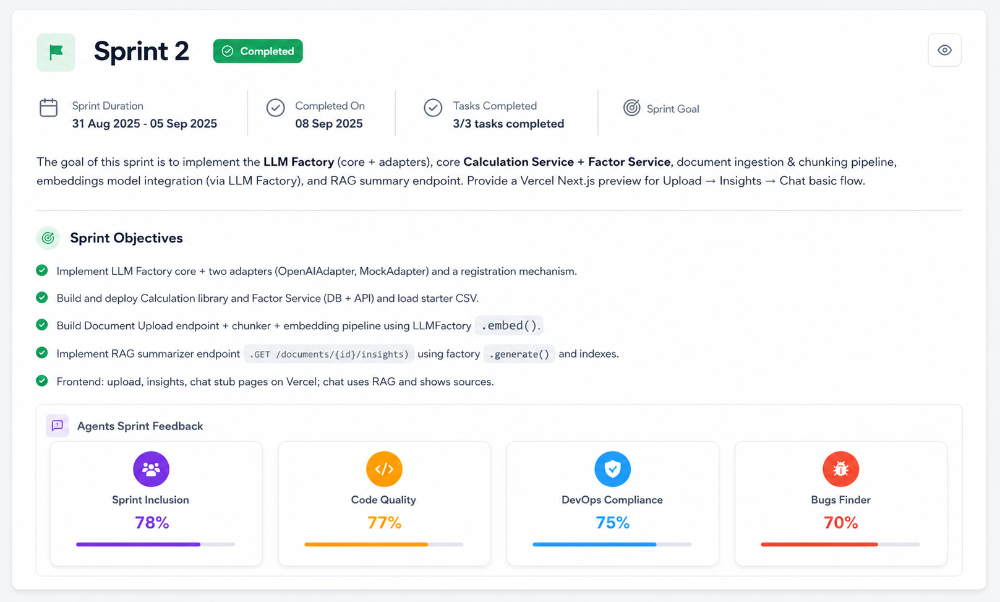
Figure 14. A completed sprint in Umaku, with all four agent scores attached. Velocity tells you the sprint shipped. The four scores tell you whether it shipped what was planned, in production-ready shape, against the right contracts, without known bug shapes.
9. What CTOs should change next quarter
Three concrete moves. None of them require a quarter to start.
Make the missing layer visible. Pick one production service. Print its current readiness across the four pillars — runbook presence, alarm coverage, DLQ wiring, ownership clarity. The exercise alone surfaces where you stand.
Move the gate from deploy to sprint. If your readiness check happens at deploy time, the engineer who wrote the change is already on the next thing. Move it to the end of the sprint. Same check, ten times cheaper to act on.
Score the layer instead of inspecting it. A static checklist becomes a vibes-based exercise within two months. A computed score — one that reads the actual diff and produces a number — survives turnover, scales with the team, and is testable against the incident rate.
Umaku DevOps Compliance gives you the third one. The first two are policy moves you can make tomorrow.
Takeaway
Production AI is less about the model and more about the layer around it. Production software is less about the feature and more about the layer around it. The two statements are the same statement, and the missing layer they both describe is the difference between sprints that look productive and sprints that are productive.
Code is cheap now. The layer that turns code into systems is the new currency. Spend it where it counts.
| NEXT STEP
Pick one production service. Score it against the four pillars this week. If any pillar is below 80, the next incident review will name the pillar. Umaku can run the same audit on every active sprint in 30 days — and start closing the gap in the same window. |
Build with clarity, deliver with confidence.
