Loading
Code Got Cheap. Context Got Expensive.
Discover why AI-assisted development shifts software costs from coding to integration, reviews, and context, and how engineering teams can adapt.

Prince Okon
Senior Data ScientistJun 26, 2026
13 minutes read

Building software got much cheaper. Keeping it working, understood, and owned did not — and on many teams it now costs more. This piece is for the CTO who has to explain that new cost to the CFO, and the VP of Engineering trying to budget for what AI-assisted development is really doing to the cost of software.
A three-engineer team ships in one quarter what took twelve engineers to ship in 2022. The PM dashboard is green. Velocity has never looked better. The on-call rotation tells a different story: bugs that did not show up in tests, cloud resources nobody can trace back to a ticket, a refund flow that three engineers all sort-of own and none of them fully understand. The CFO stares at the engineering bill, wondering why “AI-augmented productivity” has not cut spend. The CTO stares at the same number, wondering why it has gone up.
1. The Old Bill
Software used to cost what engineers cost. That sentence sounds trivial. It was the most important thing about engineering economics for two decades.
A product cost about what its engineer-hours cost. Tools were cheap. Cloud was cheap-ish. The bottleneck was the keyboard.
The old bill was big, but easy to read.
2. The New Cost Curve
Two things changed at once.
The first is well known: writing code got far cheaper. GitHub’s own studies put Copilot users at roughly 55% higher task-completion throughput. Cursor, Claude Code, Windsurf, and a long tail of vibe-coding tools now do much more than autocomplete — they scaffold whole features, write tests, and refactor. A skilled solo engineer in 2026 produces in a day what a team of four produced in a week in 2022.
The second is less publicised and more interesting: the cost of integrating that code into a system you can actually run, understand, and own has not fallen at all. On many teams, it has risen.
METR’s 2025 study of experienced engineers using AI tools on mature codebases produced a result that should have made bigger waves than it did: on real production work, the engineers were sometimes slower than without the tools. Not because the tools were bad — but because all that extra code created proportionally more work to review, integrate, and reconcile, and that work fell on the same senior engineers who were already the bottleneck.
DORA’s research shows the same shape: in AI-assisted teams, changes reach merge faster, but they fail more often once shipped, and review now eats a bigger share of the total time than it did three years ago. The cost did not disappear. It moved.
The Stack Overflow 2025 Developer Survey adds the sentiment layer: adoption of AI coding tools is up sharply, and developer trust in the output of those tools is down sharply. Engineers are using these tools more and trusting them less.
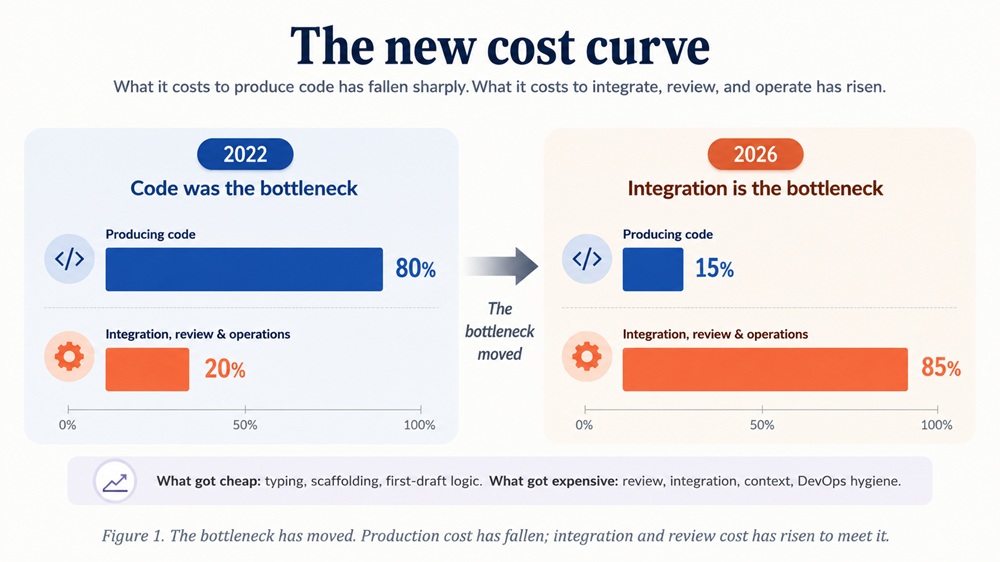
The New Cost Curve
So: production is cheap. Integration is expensive. Trust is scarce. That is the new cost curve.
3. Where the Cost Migrated To
Here are five specific line items that are now driving more of your engineering spend than they were two years ago, in rough order of magnitude.
- The review backlog. When a team’s production rate triples and the review pool stays the same, queues form. The PR that sat for two hours in 2022 now sits for two days, because three more landed behind it before the reviewer could open their laptop. The cost shows up as latency you can measure, and as context loss you cannot.
- Context reconstruction. Every engineer who touches an AI-assisted change has to reconstruct why the assistant made the choice it made. Was that retry-with-jitter on line 47 deliberate? Was that schema field rename intentional? Was that error handler the assistant’s idea or the engineer’s? The cost is measured in senior-engineer minutes per PR, multiplied by the number of PRs. It is the largest hidden line item in modern engineering.
- Integration debt. AI assistants are great at writing code that makes sense on its own. They are weaker at writing code that fits the rest of the system: what a module is meant to do, what a service promises through its API, the security rules that cut across everything. The bugs that result don’t look like normal bugs in the logs. They look like working code in the wrong place — scope drift. Disciplined teams catch them in review, average teams in staging, and tired teams in the incident channel.
- DevOps drift. Infrastructure changes are an underrated frontier for AI tools, and an underrated source of operational debt. A Terraform diff that provisions a new queue is plausible-looking, deploys cleanly, and quietly ships without a dead-letter queue, an alarm, a runbook, or an owner. Two weeks later, the on-call engineer is reading the queue’s CloudWatch metrics for the first time at 3 a.m. The cost shows up as MTTR, not as code review.
- Ownership ambiguity. When three engineers all generate code in the same module in one sprint, and none of them remembers writing the line that broke, no one really owns it. And when ownership is unclear, incidents take longer to fix, new hires take longer to ramp up, and big decisions stall. That is the hidden cost of fast individual output.

Five Hidden Line Items
A worked example: the refund that passed every test
Here is what drift looks like up close. Asked for a refund endpoint, an AI assistant returns the function below — short, readable, and green on every unit test. In the demo it works, so a non-technical reviewer signs off and the dashboard stays green.

Slop Code Ships Green Breaks in Production
None of the three defects fire on the happy path. They fire on the unhappy one — a retry, a missing order, a real refund in real currency — the path the demo never takes and the dashboard never measures. It reached production not because it looked broken, but because it was the wrong working code.

The Gap a Velocity Dashboard Can’t See
Where Umaku catches the drift
Three of the five line items above — review backlog, integration debt, DevOps drift — share a single root cause: drift is shipped because tired humans cannot reliably spot it during review. Umaku’s Code Quality agent closes that gap. It reads each diff against the module’s stated intent and surfaces the specific lines where the diff has drifted out of contract. Reviewers stop hunting for what is wrong and start adjudicating what the agent already found.
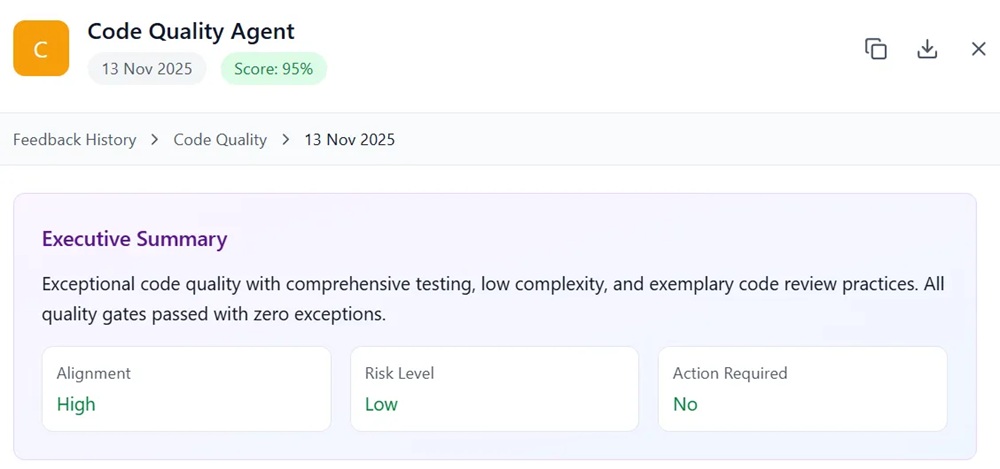
The Umaku Code Quality agent’s executive summary card — the score, the alignment risk, and the specific action it is asking the reviewer to take.
4. The Real Currency
If production is cheap and integration is expensive, what is the actual scarce resource?
It is context — being able to link any line of code back to the why behind it: the decision that produced it, the ticket that paid for it, the reviewer who approved it, and the rules it has to follow. Quickly, and with receipts. Teams that can’t do this pay an extra tax on every PR, every new hire, and every incident.
This is not a “write more docs” argument. Wikis can’t do this. What can is a queryable graph: your code, tickets, ADRs, post-mortems, and people linked together so an engineer — or an AI assistant — can ask a question and get a cited answer.
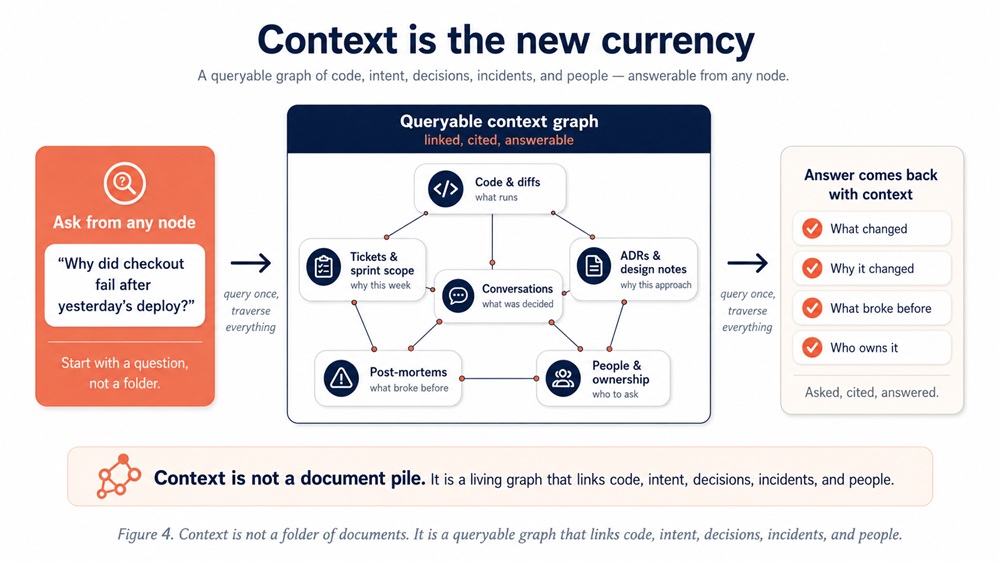
Context Is the New Currency
What “queryable” looks like in Umaku
This is what the queryable graph looks like in practice. An engineer wants to know why the billing service was split from notifications. She does not search the wiki. She does not Slack the team. In her IDE — connected to Umaku via the MCP integration — she asks the chatbot:
| ASK UMAKU
Why did we put billing on its own queue, separate from notifications? |
| CITED ANSWER · 8s
Per ADR-0023 (drafted by Mei, approved by Tunde, 18 March 2025), billing was separated because it requires strict ordering and idempotency guarantees that notifications do not need. Linked tickets: UMK-298 (queue refactor) and UMK-301 (notification fanout). PR #847 implemented the split — reviewer Sai noted the dead-letter policy in the comment thread. Owner today: the payments squad. |
In eight seconds and with the help of Umaku, she could cite the decision, the funding ticket, the implementing PR, the reviewer, and the current owner. All these were returned together as a graph query, not a document search. That is the queryable property in action. It is what turns context into something the company owns, instead of something only a few people remember.
| THE THESIS IN ONE LINE
When code is cheap, your real limit is no longer engineer-hours. It is how well the people and agents working inside your system can actually understand it. |
5. What CTOs Should Budget for Next Quarter
Three concrete moves. None require a quarter to start.
Audit your context. Pick one production service. Ask one engineer one question — “why does this function exist?”. Time the answer. Then ask the same question of every senior engineer who could be paged for that service. The median time tells you whether the context is queryable or oral.
Move judgment work into review. Treat it as the highest-leverage hour in a senior engineer’s day. Drift caught in review costs ten times less to fix than drift caught in staging, and a hundred times less than drift caught in production. Give the review process tools that do real work, instead of relying on tired humans to catch what eighteen lines of plausible code quietly broke.
Measure what changed, not what shipped. Velocity is now misleading by default. Replace or supplement it with: alignment (closed tickets matched to merged commits), time-to-context (median seconds to answer a sampled architectural question), and agent-flag rate (drift caught at PR vs. drift shipped to prod). These three numbers tell you, sprint by sprint, whether your judgment layer is keeping up with your production layer.
Three numbers worth tracking. None of them appear in a standard velocity dashboard.
What this looks like in a sprint dashboard
All three of those metrics live on a single Umaku dashboard, refreshed at every sprint close. The four post-sprint agents — Sprint Inclusion, Code Quality, DevOps Compliance, and Bugs Finder — each score one dimension of the sprint. The retro starts with a real number, not a vibe.
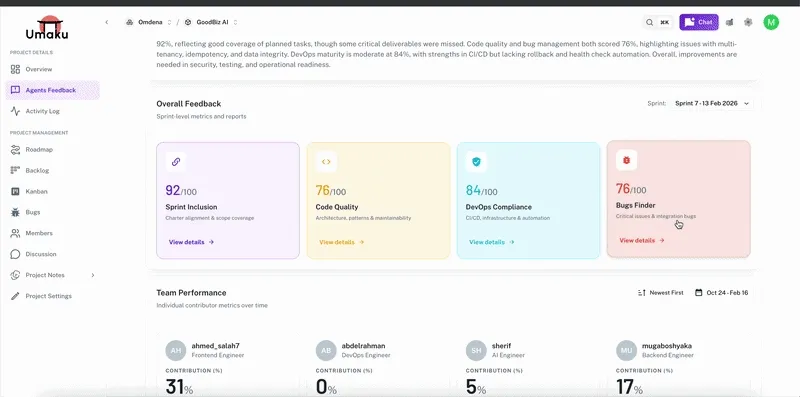
The Umaku post-sprint dashboard. Each agent surfaces one of the new metrics; together they describe whether the sprint that shipped is the sprint the team planned.
Umaku is one expression of the tooling that makes these three moves practical. It is not the only one. The shift it serves will outlast any individual vendor.
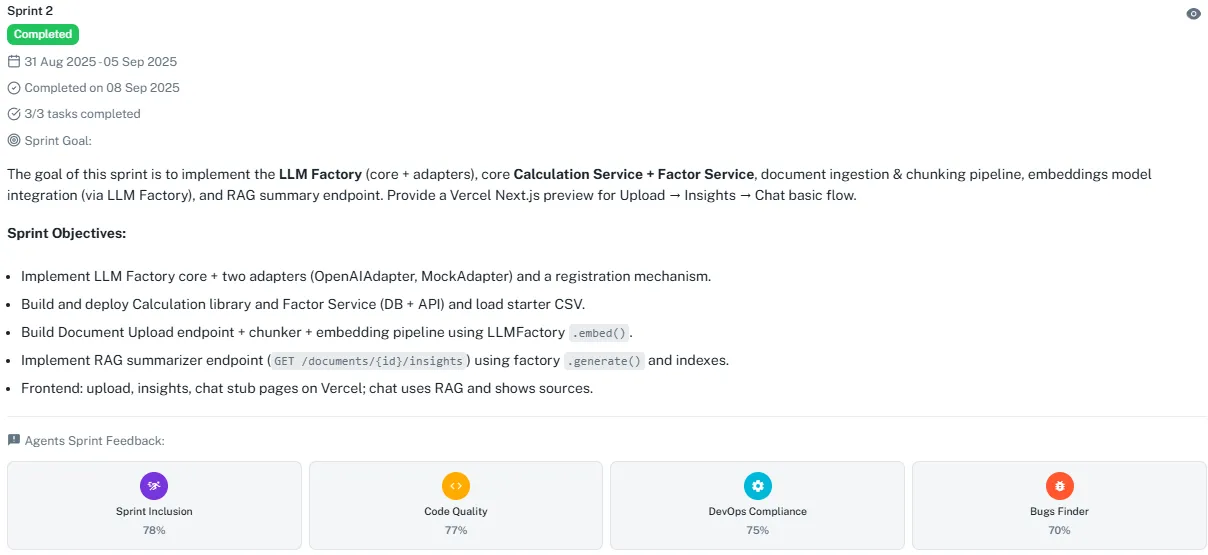
A completed sprint with the four agent scores attached. Velocity tells you the sprint shipped. Alignment tells you whether it shipped what was planned.
6. Alignment Is an Ethics Problem, Not Just a Quality One
Cheap code raises a question the old cost structure never forced: who is responsible for a change nobody fully wrote? When an agent writes the refund bug and a tired human approves it, no one clearly is. That gap is where real harm ships — overcharged customers, leaked data, a quietly biased model — with no one able to trace how it happened.
The answer is not to slow down; it is to make four practices non-negotiable: provenance, so every change traces to the intent that funded it; a human in the loop, accountable for every merge; contract and policy checks, so code honours its contracts; and auditability, so decisions are cited rather than remembered.
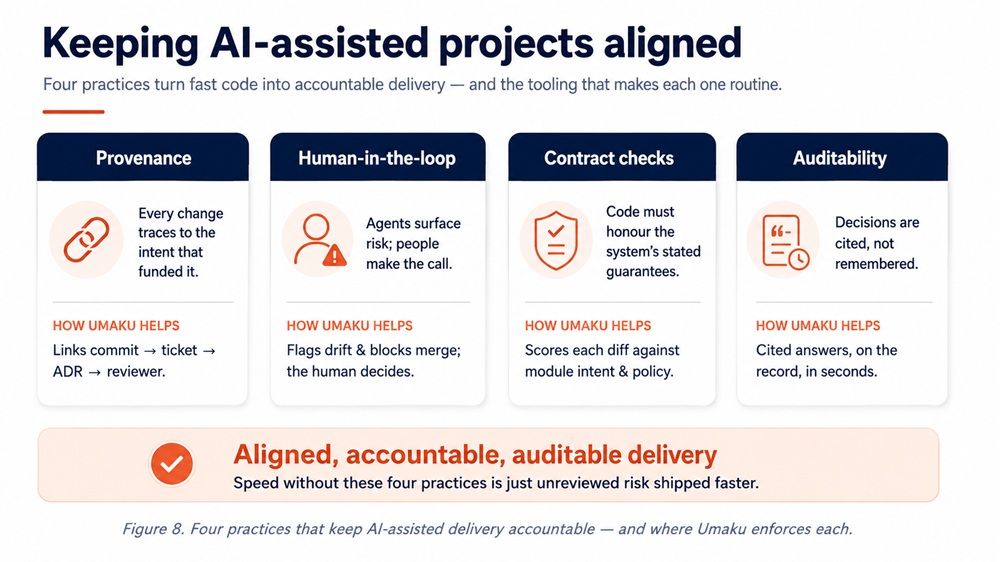
Keeping AI Assisted Projects Aligned
This is the work Umaku is built for. It scores each diff against the module’s stated intent, blocks a merge that drifts out of contract, and hands the reviewer a cited list. The same refund function arrives flagged — wrong units, missing idempotency key, state set before settle — each tied to the decision it violates.
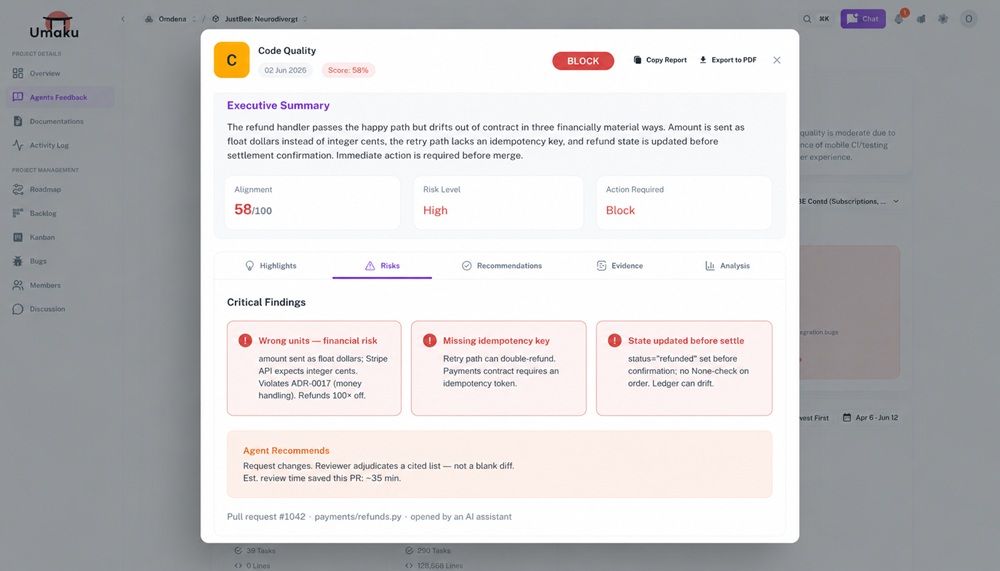
Umaku flags the refund function before it merges — every finding tied to the policy or decision it breaks. Stylized mockup, to be swapped for a live capture.
Closer
The 2022 engineering bill was high and legible. The 2026 engineering bill is lower per line of code shipped, but higher per system you can actually operate, evolve, and trust. That difference is what AI-assisted engineering is really doing to the cost structure of software. It is moving the expensive part somewhere it is harder to see.
The CTOs who treat context as the new currency — budget for it, measure it, build the infrastructure to keep it queryable — will spend the next eighteen months compounding. The ones who keep optimising for code volume will keep wondering why the line item will not shrink.
Less archaeology. More evidence.
| NEXT STEP
If you are rebudgeting your engineering org for an AI-augmented year, start with a context inventory: which decisions are documented, which are linkable to the code they govern, which would survive the team that wrote them. Umaku can run that audit on your repo in 30 days. |
![]()
Umaku is built by Omdena to help engineering teams close the gap between what they intend to build and what actually ships. We’re working on the judgment layer of modern engineering: context-aware code review, alignment between intent and artifact, and a queryable knowledge base that engineers — and the agents they work with — can ask questions of. Comments, critiques, and pushback are welcome.